도입
- 선형 회귀 모델을 위해서는 다음과 같은 연산 식을 수행해야 함.
-
아래 식 처리에 대한 편의성 확보를 위해서는 numpy를 활용 해야 함.
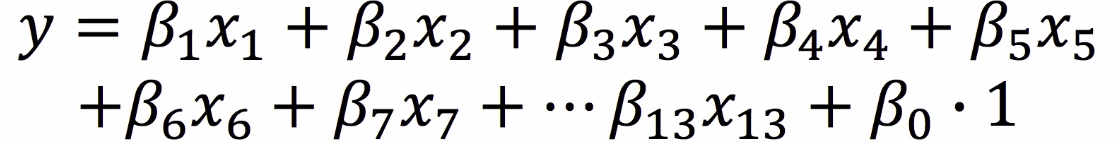
-
numpy를 통해 메트릭스 연산을 수행할 수 있기 때문임.
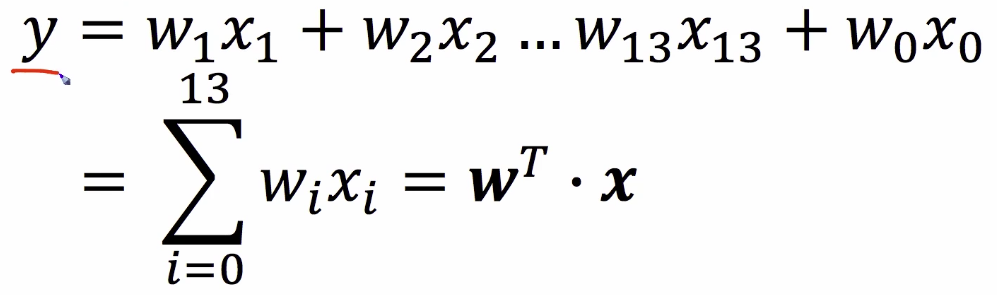
numpy 설치
source activate ml_scratch #가상환경실행
conda install numpy #numpy 설치
jupyter notebook #주피터 노트북 실행
메트릭스 연산 예제
-
연산 예제 식
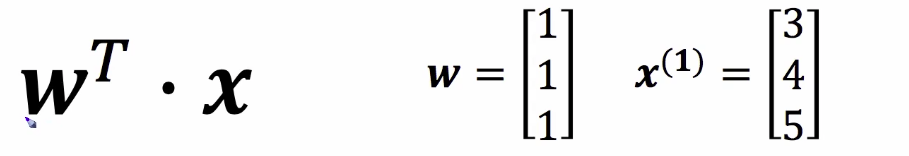
-
numpy 라이브러리 설치
import numpy as np -
예제 벡터 만들기
w_vector = np.array([[1],[1],[1]]) x_vector = np.array([[3],[4],[5]]) -
벡터 출력
[In] w_vector [Out] array([[3], [4], [5]]) -
메트릭스 연산
[In] w_vector.T.dot(x_vector) [Out] array([[12]])
pandas를 통한 로딩 데이터 메트릭스 연산
-
연산해 볼 식

y = w1*x1 + w2*x2 + w3*x3 + ... + w13*x13 + w0*1 -
pandas 라이브러리 설정
import pandas as pd -
예제 데이터 로딩
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' #Data URL df_data = pd.read_csv(data_url, sep='\s+', header=None) #CSV 데이터 로드, separates는 빈공간, Column은 없음 df_data.columns = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDY'] df_data.head() -
로딩 결과
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT MEDY 0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296.0 15.3 396.90 4.98 24.0 1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242.0 17.8 396.90 9.14 21.6 2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242.0 17.8 392.83 4.03 34.7 3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222.0 18.7 394.63 2.94 33.4 4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222.0 18.7 396.90 5.33 36.2 -
데이터 첫 번째 배열 출력해 보기
df_data.values[0] -
출력 결과
array([6.320e-03, 1.800e+01, 2.310e+00, 0.000e+00, 5.380e-01, 6.575e+00, 6.520e+01, 4.090e+00, 1.000e+00, 2.960e+02, 1.530e+01, 3.969e+02, 4.980e+00, 2.400e+01]) -
열 추가 해보기
df_data['W0'] = 1 #weight 0 값 추가 df_data.head() -
열 추가 결과
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT W0 0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296.0 15.3 396.90 4.98 1 1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242.0 17.8 396.90 9.14 1 2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242.0 17.8 392.83 4.03 1 3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222.0 18.7 394.63 2.94 1 4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222.0 18.7 396.90 5.33 1 -
열 삭제 하기
df_data=df_data.drop("MEDY", axis=1) df_data.head() -
임의의 weight 벡터 생성하기
df_matrix = df_data.values #Matrix Data로 변환하기 w_vector = np.random.random_sample((14,1)) -
벡터 연산 하기
y_vector = df_matrix.doc(w_vector) -
결과 확인
[In] y_vector [Out] array([[461.74115331], [440.98431883], [423.45917427], ...<중략> -
y_vector shape 확인
[In] y_vector.shape [Out] (506, 1)



댓글남기기